M4ndU 600점 10등
REV 50
FOR 50
MISC 50 100 150 200
[2019] 제17회 청소년 정보보호 페스티벌(YISF)_문제풀이보고서_M4ndU.docx
0.42MB
[2019] 제17회 청소년 정보보호 페스티벌(YISF)_문제풀이보고서_M4ndU.pdf
0.41MB
두개 모두 동일한 내용의 파일입니다.
아래 글에는 보고서에 포함된 내용 + 풀이 과정 비하인드(?) + MISC 300 문제 풀이 일부를 포함하고 있습니다.
Reversing 50
문제 이름
기밀 문서
문제 설명
이 문서에는 엄청난 것이 들어있는게 분명하다 . 무엇이 들어있는지 확인해볼까 ? TOP_SECRET Hint1 : 특정 폴더와 파일 이름 ? Hint2 : 비밀번호 변조
TOP_SECRET이라는 파일이 하나 주어집니다.
ELF 64bit file
Exeinfo PE로 보면, ELF 64비트 파일임을 알 수 있습니다.
main함수
sub_B2F함수
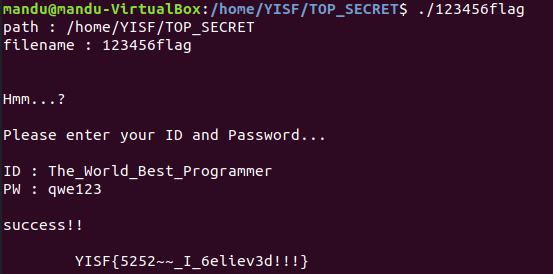
IDA로 까보면, 실행경로와 파일명을 출력해주고, id와 pw를 입력받는 것을 알 수 있습니다.
sub_B2F함수의 42행을 보면, 실행경로의 7번째 글자부터 4바이트가 YISF인지 비교를 합니다.
있을 경우, Hmm...?을 출력해줍니다.
그리고 실행경로의 12번째 글자부터 10바이트를 TOP_SECRET와 비교합니다.
있을 경우, id와 pw을 입력을 받습니다.
id
pw
id와 pw는 변수명을 더블클릭하면 문자열을 보여줍니다.
id = The_World_Best_Programmer
pw = qwe123
따라서 TOP_SECRET파일을 /home/YISF/TOP_SECRET/ 으로 이동시켜서 실행하면 됩니다.
너 속았냐?
하지만 이렇게 출력된 플래그는 인증이 안됩니다. 조건을 하나 더 충족시켜야 하는데요. main함수를 다시 보시면 20번 행에서 파일명의 7번째부터 4바이트를 "flag"와 비교함을 알 수 있습니다.
따라서 파일명도 바꿔주어야 합니다. 저는 파일명을 123456flag로 변경하였습니다.
오이 오이 믿고 있었다구!!
그러면 인증가능한 플래그가 출력됩니다.
Forensic 50
문제 이름
범죄를 증명하라 (1)
문제 설명
마약관련 범죄를 저지른 범죄조직을 감시하던중 네트워크를 통해 정보를 주고받았다는 제보를 받았다 . 패킷을 수집하였으나 분석을 할 수 있는 사람이 없어 분석을 못하고 있다 . 수사기관을 도와 분석을 마무리하자 . < 제보 1> 익명의 제보자는 조직원들이 FTP 를 이용하여 파일을 공유했다라고 한다 . < 제보 2> 익명의 제보자는 recovery 라는 메시지를 남긴 채 연락이 두절되었다 ..... < 제보 3> 연락 두절된 제보자가 image.zip 을 복구하라는 메세지를 보냈다 !
작년 처럼 포렌식으로 점수먹으려다가 첫 문제에서 10시간이상 소비한 문제...
일단 힌트가 없었을때, wireshark로 분석했을 때, 크게 2~3개정도로 나눌 수 있었습니다.
1. 아프리카tv 패킷
2. ftp 패킷
3. websocket 패킷
websocket 패킷을 봤을 때 사람 이름들이 나오길레 이건가 싶었는데... 결론은 관련이 없었습니다. 아프리카tv쪽에서 나온 패킷인 것 같습니다. (추측)
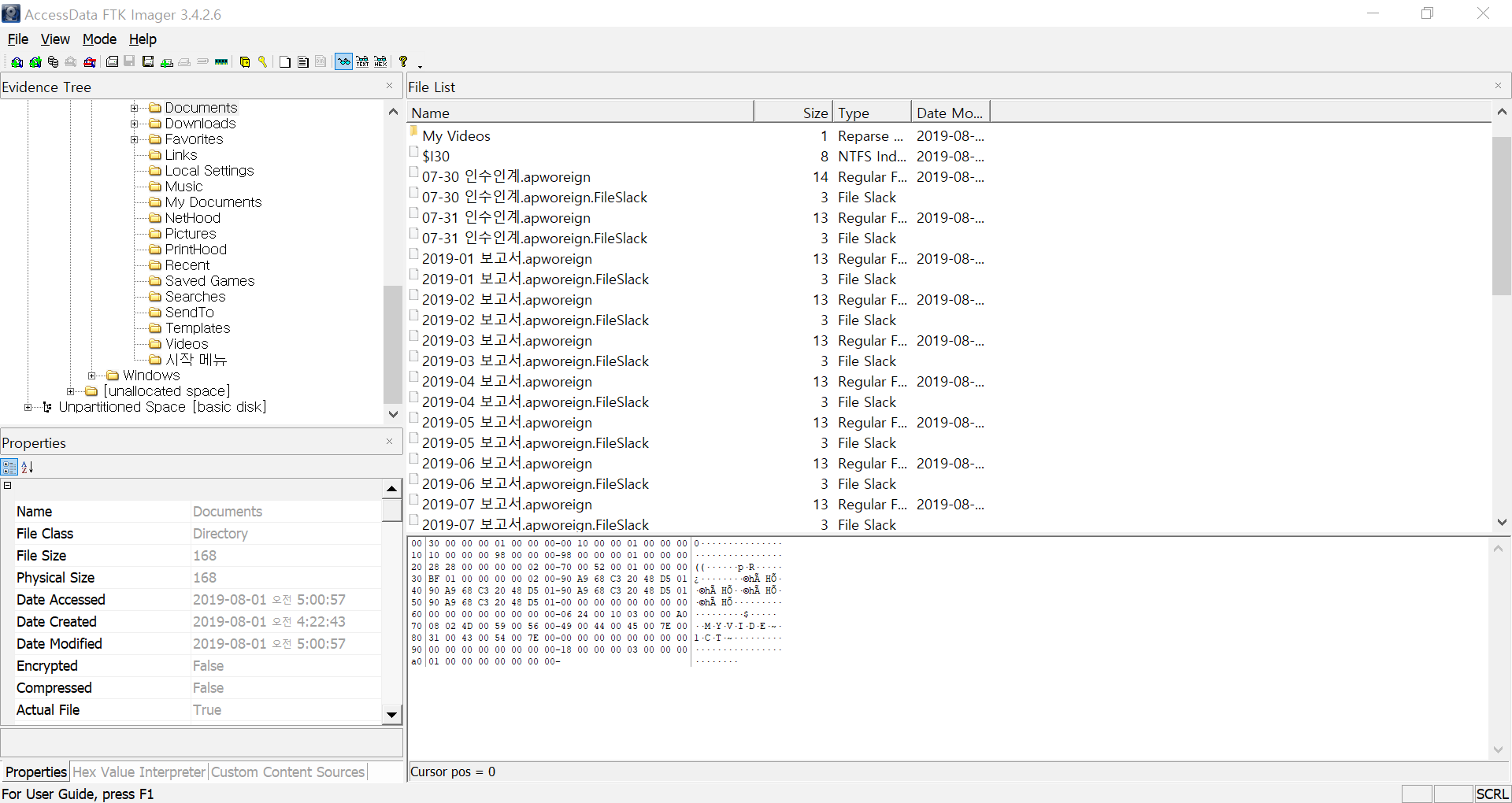
힌트1 <제보1>을 통해서 ftp패킷을 분석함이 확실해져서 ftp-data패킷만 모아서 파일들을 추출하였습니다. wireshark 필터에 (ftp-data)을 입력하면 해당 패킷만 모아 볼 수 있습니다. 그리고 패킷 우클릭 > follow > TCP Stream
RAW > save as > 추출!
image.zip 파일, 기차 이미지 파일 2개, 멜론 설치 파일
총 4개의 파일을 얻을 수 있었습니다. image.zip파일이 오류로 열리지 않느 것 빼곤 나머지 파일은 정상이었습니다.
HxD로 봤을 때, image.zip파일이 열리지 않는 이유가 일단 파일 크기가 매우 크게 설정된 것도 있었고, 파일 명도 읽을 수 없는 형태였습니다. zip파일 시그니쳐가 손상된 것도 아니고... 제가 아는 복구 방법으로는 해결을 못했습니다.
그렇게 힌트 존버하다가... 나온 힌트들이 모두 이미 진행된 내용이라 포기하려다가
어떤 한분이 푸시고, 디스코드에 '운이 좋게 풀었다', '노가다 했다'라고 하셔서 저도 풀 수 있을 것 같다는 생각이 들었고 구글링을 시작했습니다. "ctf zip 복구"로 검색을 하니 블로그 글 하나를 찾을 수 있었습니다.
https://m.blog.naver.com/PostView.nhn?blogId=j28150&logNo=220993474255&proxyReferer=https%3A%2F%2Fwww.google.com%2F
[Plaid CTF 2017] zipper (Misc 50pts)
Something doesn't seem quite right with this zip file. Can you fix it and get the flag?zip파일 헤...
blog.naver.com
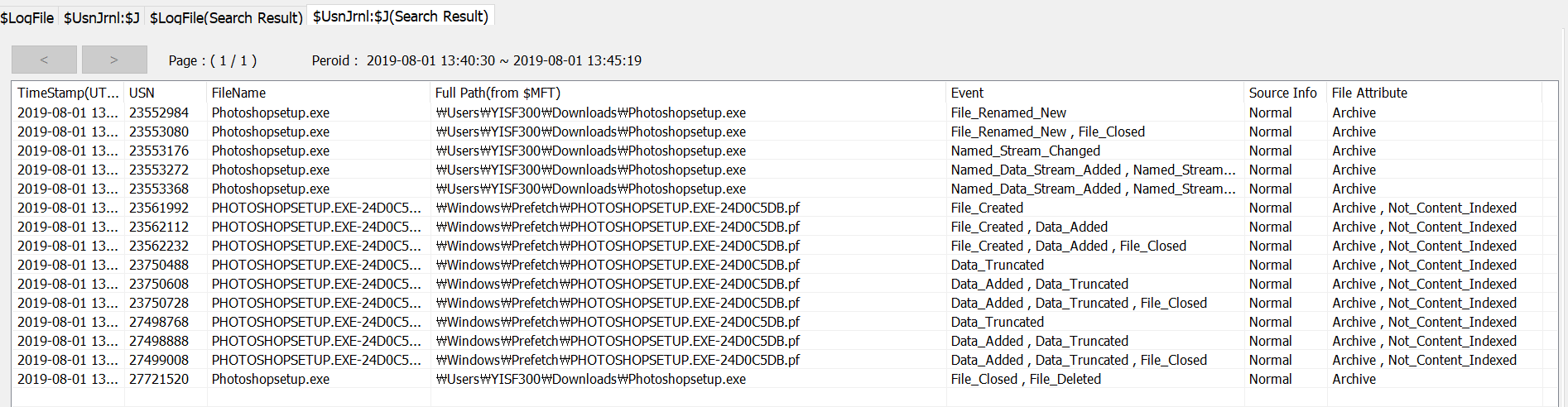
위 블로그 글에 나온대로 풀려고 했는데, 주어진 zip파일은 파일 크기 부분이 정상이 아니었기 때문에, data부분의 정확한 크기를 알 수 없었습니다. 그래서 1바이트씩 줄여가며 시도할 생각으로 0000이 끝나는 부분을 기점으로 추출해서 zip파일을 만들고 파이썬 코드로 압축 풀기를 시도했습니다.
image.zip dat부분
data 부분을 추출하여 만든 image.zip
s.py
import zlib
d = open ('image.zip' ).read()
print zlib.decompress(d, - 15 )
cs
python s.py
실행결과 :
FLAG : YISF{Y0U_4R3_G00D_H0M3_M4K3R}
띠용.. 플래그가 바로 나와버렸습니다...
Misc 50
문제 이름
룰 확인
문제 설명
룰을 확인하세요 !
대회의 룰을 읽고 하단의 ‘ 확인을 클릭하면 ’ 플래그가 나왔습니다 .
FLAG : YISF{G00D_LUCK_3V3RY01V3}
Misc 100
문제 이름
Hidden area search
문제 설명
nc 218.158.141.199 24763 매 문제마다 새로운 직선방정식 3 개가 주어진다 . 이 직선방정식들로 만들어진 삼각형의 넓이를 구하여라
일차방정식 3 개를 입력받아 , 각각 두 방정식끼리 연립해서 교점을 구하고 , 세 점의 좌표를 알 때의 삼각형 넓이 공식에 대입하여 넓이를 구하였습니다 .
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
from sympy import *
from pwn import *
def cleaneqn(s):
s = str (s)
s= list(map(str , s.split()))
s[0 ] = s[0 ].replace("b'" , "" )
s[6 ] = s[6 ].replace("\\n'" ,"" )
if int (s[3 ])< 0 :
ss = s[0 ]+ "*" + s[1 ]+ s[3 ]+ "*" + s[4 ]+ " " + s[6 ]
else :
ss = s[0 ]+ "*" + s[1 ]+ s[2 ]+ s[3 ]+ "*" + s[4 ]+ " " + s[6 ]
return ss
def solveeqn(a1, a2): #연립방정식 풀어서 x와 y값 구하기
x, y = symbols('x y' )
a1 = a1.split()
a2 = a2.split()
return eval("solve( [ Eq(" + a1[0 ]+ " ," + a1[1 ]+ "), Eq(" + a2[0 ]+ ", " + a2[1 ]+ ") ], [x,y] )" ) #입력 형태 맞춰 넣기가 애매해서 eval함수 사용했습니다.
def solve_func(e):
x, y = symbols('x y' )
for i in range (0 ,3 ):
e[i] = cleaneqn(e[i]) #입력받은 방정식을 sympy가 입력받을 수 있는 형태로 변환
ss1 = solveeqn(e[0 ], e[1 ]) #교점 좌표 구하기
ss2 = solveeqn(e[1 ], e[2 ])
ss3 = solveeqn(e[0 ], e[2 ])
x1 = ss1[x]
y1 = ss1[y]
x2 = ss2[x]
y2 = ss2[y]
x3 = ss3[x]
y3 = ss3[y]
ans = 0. 5 * abs((x1 - x2)* y3 + (x2- x3)* y1 + (x3- x1)* y2) #각 꼭짓점의 좌표를 알 때의 삼각형 넓이 공식
return ans
#main
equation = ["0" ]* 3 #방정식을 저장하기 위함
p = remote("218.158.141.199" , 24763 )
p.recvuntil("Start>" )
p.recvline()
p.recvline()
for i in range (0 , 100 ):
print (p.recvline()) #step
p.recvline()
equation[0 ] = p.recvline()
equation[1 ] = p.recvline()
equation[2 ] = p.recvline()
for j in range (0 , 3 ):
print (equation[j])
p.recvuntil(":" )
p.sendline(str (solve_func(equation)))
print (p.recvline()) #correct
p.recvline()
p.interactive()
#flag : YISF{Mathematical_ability_i5_n0t_ru5ty}
cs
Misc 150
문제 이름
Rule_reverse_engineering
문제 설명
[MISC-150]Rule_reverse_engineering nc 218.158.141.182 52387 실행마다 예시인 문자열이 달라지는데 바이너리값은 같을 때가 있다 . 같은 것을 보면 문자열에서 바이너리로 변하는 일정한 규칙이 있는 것 같다 . 규칙이 적용된 문자열이 주어진 바이너리와 같도록 문자열을 입력해라
Step : 1
table이 주어집니다. 오른쪽에 해당하는 문자열을 왼쪽 문자로 치환해주면 됩니다.
치환해야할 문자열이 긴 것 부터치환을 하면 됩니다.
그런데 치환한 문자가 0이나 1이면 치환해야할 문자로 판단하여 또 치환해버립니다.
그래서 치환한 문자가 0이 1이면 전혀 다른 범위의 문자로 바꾸었다가 마지막에 되돌려 놓았습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
from pwn import *
import ast
def ccccc(h):
h = h.replace('b"table : ' , "" )
h = h.replace('\\n"' , "" )
print (h)
inn = ast.literal_eval(h) #type dictionary
return inn
def ddd(e):
e = e.replace("b'" , "" )
e = e.replace("\\n'" , "" )
return e
def ans(innn, task):
innn = ccccc(innn)
ss = sorted(innn, key= lambda k : innn[k]) #치환 대상 문자열의 길이가 긴 순서대로 치환
task = ddd(task)
for j in ss:
p= j
if j = = "1" : #치환 대상의 문자열과 동일한 0 과 1을 범위 밖의 문자로 치환하여 나중에 다시 되돌림
p = "#"
if j = = "0" :
p = "@"
task = task.replace(innn[j], p)
task = task.replace("#" , "1" )
task = task.replace("@" , "0" )
print (task)
return task
#main
p = remote("218.158.141.182" , 52387 )
p.recvuntil("Step : 1" )
p.recvline()
p.recvline()
for i in range (0 , 99 ):
try :
t = p.recvline() #task
p.recvline()
table = p.recvline() #table
p.recvuntil(": " )
p.sendline(ans(str (table), str (t)))
print (p.recvline())
p.recvline()
p.recvline()
p.recvline()
print (p.recvline())
print (p.recvline())
except :
p.interactive()
t = p.recvline() #Stage 100
p.recvline()
table = p.recvline()
p.recvuntil(": " )
p.sendline(ans(str (table), str (t)))
p.interactive()
#flag : YISF{Y0u_make_table_WeLL}
cs
Misc 200
문제 이름
Find First!
문제 설명
nc 218.158.141.142 9238 처음 시작 위치를 찾아라 ! [ 설명 ] 1. 모든 버튼은 전부 한번 씩 눌려야 하고 항상 마지막으로는 F 가 눌립니다 . 2. 배열의 시작은 왼쪽 위 ( (x, y)=(0, 0) ) 이고 x 와 y 의 값은 0 과 양의 정수 입니다 . 3. 버튼의 처음 시작 위치를 문제당 1 초 안에 찾으십시오 . 4. 배열의 행과 열의 크기는 5 이상 , 10 이하 입니다 . 5. 문자는 다음 버튼의 위치를 나타내고 숫자는 이동 칸 수를 나타냅니다 . 5-1) D = Down, U = Up, R = Right, L = Left 5-2) Ex) D5 = 아래로 5 칸 , R3 = 오른쪽으로 3 칸 6. 모든 스테이지를 클리어 하면 플래그가 주어집니다 .
[?] Input Example
쉽습니다. 일단 F에서부터 출발할 필요가 없습니다. 중간에서 찾아가도 시작점은 나오니까요.
시작점을 (0,0)에서부터 시작해서 위 아래 양옆 기준으로 이전 위치를 찾아갑니다.
이전 위치가 위라면 n칸만큼 떨어진 곳에 Dn이 있을 것이고, 왼쪽이라면 Rn이 존재할 것입니다. 이러한 방식으로 이전 위치를 찾고, 이전위치를 기준으로 다시 더 이전 위치를 찾습니다. 모든 방향으로 조건에 만족하는 것이 없다면 그 곳이 시작위치가 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
from pwn import *
import re
def ddd(e):
e = e.replace("b'" , "" )
e = e.replace("\\n'" , "" )
return e
def cntarr(col): #count element in first line / range of x
col = ddd(col)
col = col.replace("\\t" , "" )
col = col.replace("F" , "FF" )
col = col.replace("\\r" , "" )
cnt = int (len (col) * 0. 5 )
return cnt
def ans(b, c, d):
for o in range (0 , d):
a[o] = ddd(str (a[o]))
a[o] = a[o].replace("\\t" , "" )
a[o] = a[o].replace("\\r" , "" )
a[o] = a[o].replace("F" , "FF" )
aa = a[o]
print (a[o])
a[o] = re.findall(r'..' ,aa)
print (a)
now_x = 0 #F부터 시작할 필요가 없음. (0,0)지점부터 시작
now_y = 0
overcnt = 1
while (overcnt > 0 ): #시작위치를 찾아내면 루프를 벗어남
#현재 위치가 시작점이 아니라면, 이전 위치를 찾아야함.
#만약 이전 위치가 왼쪽 방향이라면, 왼쪽 방향 n거리 만큼에 Rn이 존재함.
#아래쪽 방향이라면, 아래쪽 방향 n거리 만큼에 Un이 존재함
for k in range (0 , 10 ): #MAX 10. scan start
n = str (k)
if now_x+ k < c: #배열 범위를 벗어나면 오류가 나기 때문에, 범위를 지정해주어야함
if now_y > = 0 and now_x > = 0 and a[now_y][now_x+ k] = = ("L" + n): #right
now_x + = k #찾은 경우, 현재 위치를 찾은 위치로 이동함
break
if now_y+ k < d:
if now_y > = 0 and now_x > = 0 and a[now_y+ k][now_x] = = ("U" + n): #down
now_y + = k
break
if now_x- k > = 0 :
if now_y > = 0 and now_x > = 0 and a[now_y][now_x- k] = = ("R" + n): #left
now_x - = k
break
if now_y- k > = 0 :
if now_y > = 0 and now_x > = 0 and a[now_y- k][now_x] = = ("D" + n): #up
now_y - = k
break
if k = = 9 :
overcnt = 0 #모든 방향에 존재하지 않는다면 현재 위치가 시작지점임
ax = now_x
ay = now_y
print (ax, ay)
return ax, ay
p = remote("218.158.141.142" , 9238 )
p.recvuntil("Problem 1\n" )
p.recvuntil("Problem 1\n" )
for m in range (0 ,99 ):
a= ["0" ]* 10
a[0 ] = p.recvline()
print (a)
count = cntarr(str (a[0 ]))
c2= 1
for i in range (1 , 10 ):
a[i] = p.recvline()
c2 + = 1
if len (str (a[i])) < 10 :
c2- = 1
break
p.recvuntil(": " )
w, z = ans(a, count, c2)
p.sendline(str (w)+ " " + str (z))
print (p.recvline())
p.recvline()
print (p.recvline())
#stage 100
a= ["0" ]* 10
a[0 ] = p.recvline()
print (a)
count = cntarr(str (a[0 ]))
c2= 1
for i in range (1 , 10 ):
a[i] = p.recvline()
c2 + = 1
if len (str (a[i])) < 10 :
c2- = 1
break
p.recvuntil(": " )
w, z = ans(a, count, c2)
p.sendline(str (w)+ " " + str (z))
p.interactive()
#flag : YISF{Y0(_)_4r3_4_w0nd3rf(_)l_pr0gr4mm3r!!}
cs
Misc 300
솔버 0이라서 그런지 지금은 문제가 닫혀있다.
nc접속을 하면, 스테이지가 100개가 있는데, 스테이지마다 매우 많은 base64인코딩 문자열을 준다.
디코딩을 하게 되면 hex값이 나온다. 이를 파일로 만들면 png파일이 나온다.
이미지를 열면 이미지에 문자가 젹혀 있고, 이 문자를 읽어서 5초안에 제출하면 된다.
그래서 생각한게, 이미지를 만들어놓고 내가 이 이미지를 바로 봐서 직접 타이핑해서 제출하는 방식이었다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
from pwn import *
import base64
import binascii
import cv2
from PIL import Image
import matplotlib.pyplot as plt
# matplotlib.image 를 사용하기 위해선 matplotlib 뿐만 아니라 pillow도 깔아야 한다
import matplotlib.image as mpimg
def show(e):
data = str (e)
data = data.replace("b'" , "" )
data = data.replace("\\n\\n['" , "" )
data2 = data.split("\\n" )
dat= ""
for i in range (0 , len (data2)):
dat + = str (base64.b64decode(data2[i]).decode('utf-8' ))
dat = dat.replace("b'" , "" )
dat = dat.replace("'" , "" )
red = dat
bin_ = ""
for j in range (0 , len (red), 2 ):
binary_d = str (red[j:j+ 2 ])
binary_d = binary_d.replace("b'" , "" )
binary_d = binary_d.replace("'" , "" )
bin_ + = "\\x" + binary_d
fh = open ("image.png" , "wb" )
eval("fh.write(b'" + bin_+ "')" )
fh.close ()
'' '
# 색상 범위 설정
lower = (0, 0, 0)
upper= (150, 150, 150)
# 이미지 파일을 읽어온다
img = mpimg.imread("image.png", cv2.IMREAD_COLOR)
# BGR to HSV 변환
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# 색상 범위를 제한하여 mask 생성
img_mask = cv2.inRange(img_hsv, lower, upper)
# 원본 이미지를 가지고 Object 추출 이미지로 생성
img_result = cv2.bitwise_and(img, img, mask=img_mask)
# 결과 이미지 생성
imgplot = plt.imshow(img_result)
plt.savefig(' ./ image1.png')
img = Image.open(' ./ image1.png')
thresh = 245
fn = lambda x : 255 if x > thresh else 0
r = img.convert(' L').point(fn, mode=' 1')
r.save(' ./ image1.png')
' ''
p = remote("218.158.141.149" , 25496 )
p.recvuntil("=\n" )
p.recvline()
for ZZZZZZZZZZZZZ in range (0 ,99 ):
b64 = p.recvuntil("[" )
show(b64)
p.recvuntil(": " )
user_input = str (input())
p.sendline(user_input)
print (p.recvline())
print (p.recvline())
print (p.recvline())
print (p.recvline())
b64 = p.recvuntil("[" )
show(b64)
p.interactive()
cs
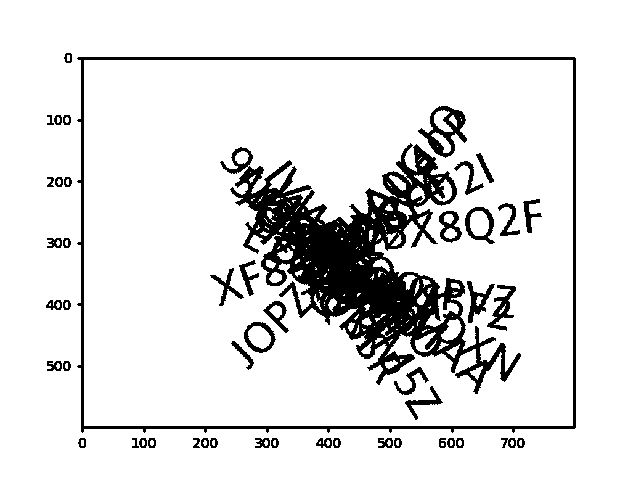
근데 이게 줄쳐진 것 때문에 사람이 읽기도 힘들다. 정확히는 비슷한 글자들로 헷갈린다.
게다가 한 스테이지마다 5초안에 입력하는걸 100스테이지를 해야하는데 직접 해보니 25스테이지 정도가 한계였다.
타임아웃뜨거나 오타나거나해서...
그래서 컴퓨터가 직접 글자를 인식해서 자동으로 보내게 해야 했다. 근데 이게 가능한가...
pytesseract을 설치해서 사용해 봤는데 인식을 못했다.
그래서 글자를 더 잘 구별할 수 있도록 회색글자부분만 추출해서 검정으로 바꾸는 코드를 추가했었다.
그런데도 인식을 못했다. 나라도 잘 봐서 직접 입력하더라도 정확도를 높이려고 했는데....
2스테이지를 넘어가면 ... 이전 이미지에 겹쳐져서 나온다. 처음 써보는 모듈이라 이걸 어떻게 해결해야 할지도 모른다..
마지막에 생각난 아이디어. 여러번 접속을 해서
base64문자열 받고 -> 이미지 변환 -> 직접 입력
직접 입력한 값과 base64문자열의 해쉬값을 db에 저장
최종실행에 입력받은 base64를 해쉬돌려서 db에 있는거랑 비교, 입력값 전송
그런데 전체 이미지 개수가 1만개가 넘어갈 수도 있을 텐데.. 이것도 안될 것 같았다. 포기